
In a paper to be presented at the Passive and Active Measurement Conference in Berlin in March 2018, Prof. Joel Sommers describes a study of the empirical characteristics of language tags used in HTTP transactions and in web pages to indicate the language of the content and possibly the script, region, and other information. The top-level pages of websites in the Alexa Top 1 Million sites were used in the study, with data gathered from six different geographic perspectives using a commercial VPN service.
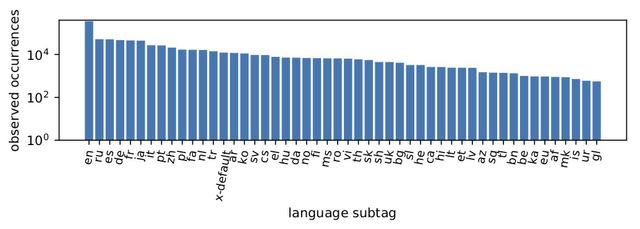
Although results vary slightly depending on geographic vantage point, the study finds that one third of all pages do not include any language tags, that half of the remaining sites are tagged with English (en), and that about 10K sites have malformed tags. About 80K sites are observed to be multilingual, and that while about 30K of those offer just two languages, there are hundreds of sites that offer content in the tens of languages. Besides a variety of malformed tags, numerous instances of correctly formed but likely erroneous language tags were also identified.
Preliminary work that led to the paper was done by students Alexandra Nie ‘20 and Ryan Rios ‘20 during the summer of 2017.
As part of this work, an open-source library to rigorously parse language tags using the Python language was created, available at https://github.com/jsommers/langtags.
Detailed results of the study may be found in the full paper, available at: https://jsommers.github.io/pubs/pam18.pdf